Redis | Bull | JobQueue
Why not Kafka/ Message Queue?
Although Kafka guarantees long durability and large scalability, but it seems to be a overkill for simple background tasks. Using Kafka is more challenging to set up and manage compared to other options.
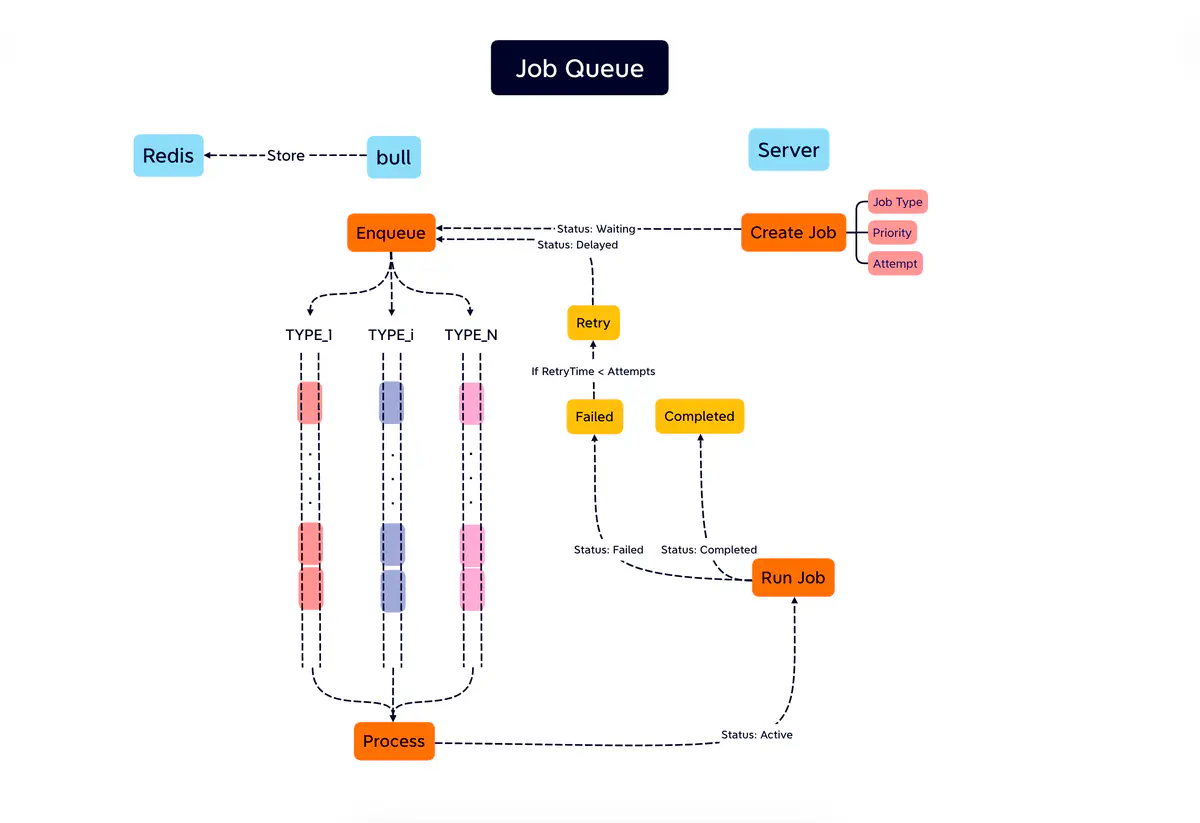
JobQueue Flow
- Configuration: Define the job type, priority, maximum attempts, and other parameters.
- Enqueue: User actions prompt the server to place jobs in the queue with an initial status of waiting.
- Processing: Jobs are processed concurrently from the queue based on their assigned priority, transitioning to an active status.
- Execution: The server executes the designated tasks for each job.
- Successful Completion: If a job executes without errors, its lifecycle concludes with a completed status.
- Retries on Failure: Should a job face execution issues but still has remaining attempts, it re-enters the queue. However, a specified delay is imposed before the next execution attempt, marking its status as delayed.
- Unsuccessful Completion: If a job fails all allotted attempts, its lifecycle terminates with a failed status.
Redis
- What is Redis?
- Redis (Remote Dictionary Server) is an open-source (BSD licensed), in-memory database, often used as a cache, message broker, or streaming engine.
- Why is Redis so fast?
- Redis holds the data in memory. The data reads and writes in memory are generally 1,000X - 10,000X faster than disk reads/writes.
- Storing data in memory allows for more flexible data structures. These data structures don’t need to go through the process of serialization and deserialization like normal on-disk data structures do, so can be optimized for fast reads and writes.
Chengzhan Gao
高程展|Software Engineer
My interests include web development, game development and machine learning.